

Why AIOps and orchestration are two different jobs and why you need both to get to agentic MIM
Let’s be clear up front about what this post is and isn’t about. This isn’t about the failed login that retries itself, or the pod that restarts when memory spikes. Those belong in the application code. This is Major Incident Management (MIM). A P1 or P2 where your usual defenses have already failed, revenue and customers are exposed, regulators are watching, and you now have to coordinate dozens of people across half a dozen teams to get the business back on its feet.
In those moments, the tooling question stops being about features and starts being about architecture. Enterprise MIM is not a product you buy from a single vendor, it’s a stack, and the vendors who tell you otherwise are selling you shallow coverage at the moment you can least afford it.
Note: throughout this post we use Mean Time To Mitigate or MTTM because that’s what the team is actually measured on. You rarely resolve a P1 inside the incident; you mitigate it and fix it properly afterwards.
The next-generation major incident management architecture
Here’s the architecture we keep coming back to with customers:
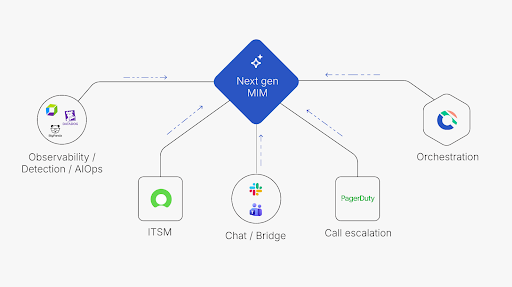
Five specialist lanes, built by each vendor with decades of investment:
- Observability/detection/AIOps: Provides signal-to-noise on alerting and runtime data (e.g. Splunk, BigPanda, Datadog).
- ITSM: Provides the system of record for the incident ticket, problem management and CMDB (e.g. ServiceNow).
- Chat/bridge: Provides real-time communication and engagement (e.g. Microsoft Teams, Slack).
- Call escalation: Provides the paging and call trees that wake the right people up (e.g. PagerDuty).
- Orchestration: Provides the system of execution across humans, agents and automation (Cutover Respond).
Next-generation MIM needs every one of these. No single vendor credibly does them all. AI and machine learning don’t paper over decades of missing domain experience, they amplify it where it already exists.
AIOps: Major incident detection, not resolution
AIOps earned its place in the architecture because modern estates generate thousands of alerts an hour, most of them noise. Good AIOps platforms cut through it: event correlation, root cause hints, 90–99% noise reduction, and the occasional automated restart for known patterns.
That’s genuinely valuable but AIOps answers a very specific question: “What is happening, and is this actually the major incident we think it is?” It was architected around ingesting telemetry, not coordinating 50 people across six teams through assembling a 40-step recovery plan on the fly with approval gates. Those are two different problems, solved by two different kinds of platform.
AIOps tells you the building is on fire. Cutover Respond runs the evacuation plan.
Orchestration: Where MTTM is actually won
Once the signal is clear and a major incident is declared, the work shifts from detection to execution. Who owns which task? What has to happen before we can fail over? Who approves the mitigation? Which steps can an agent run, and which need a human-in-the-loop? How do we keep the audit trail regulators will ask for?
That coordination doesn’t live in tickets, logs, or chat. Ticket-Ops is a system of record, Chat-Ops is a place to talk about a problem. Neither was designed to execute a complex, multi-team response with sequence, accountability and a live audit trail. That’s orchestration, and it’s the layer the industry has been missing.
Cutover Respond is purpose-built for that lane: task-based orchestration across humans, AI agents and automated systems, with approvals, dynamic runbooks, and an immutable, regulator-ready audit trail by default. It integrates with AIOps, ITSM, chat and paging - it doesn’t replace them.
The path to agentic MIM (and why it’s not a leap of faith)
Agentic MIM is the direction of travel: agents triaging signals, drafting mitigation plans, executing low-risk steps and handing the high-risk decisions to humans. Enterprise teams are rightly cautious as that jump feels large, and in a P1 you don’t get to experiment.
The good news is it isn’t a leap, and most of our customers are already on the path. Early agents that read data but don’t act on production can check recent changes on affected configuration items (CIs), scan logs for early root-cause analysis (RCA), and are a low-risk, high-value first step. The orchestration layer captures every one of those actions in the audit trail, which is what makes the next step, agents that execute, credible to risk and compliance.
From there, the direction of travel is clear. AIOps gets sharper at detection and early triage. Orchestration becomes the control plane where agents execute alongside humans inside governed, sequenced, audited runbooks. Every action, whether agent or human, lands in the same record. You get the speed of automation without losing the accountability enterprises (and regulators) require.
That’s why the architecture matters more than any single product. Agentic MIM is built by combining specialists in their lane, not by a vendor claiming to do all five things credibly.
What this looks like in practice: Six moves that actually reduce MTTM
Architecture is the enabler. Here’s what the teams winning on MTTM actually do with it:
- Get the base architecture in place. Cover all five lanes with credible partners. Shallow coverage anywhere in the stack shows up as delays in the bridge.
- Remove communications toil from your resolvers. Segment audiences so stakeholders don’t interrupt the people fixing things. Push automated, natural-language status updates out of the orchestration platform, and give the incident manager full communications oversight to intervene when needed.
- Take work out of chat. Chat is a leaky bucket where tasks get lost, ownership blurs lines, and progress stalls. Track ad-hoc tasks inside a lightweight incident framework, with stored snippets for known mitigation paths, so you stop re-discovering the same runbook on every call.
- Automate your mobilization steps. Use data-collection agents to do what you’d normally ask first responders to do, such as pull recent changes on the affected CIs, scan logs for early RCA. Start with agents that “read” but don’t “act” on production, and capture every step in the orchestration audit trail.
- Remove toil from the post-incident review. Stop tying up expensive people for days reconstructing what happened. The orchestration record is the review of what was run, by whom, with what outcome.
- Turn every incident into a reusable asset. Harvest the steps that worked into snippets you can reuse next time. Stop letting every P1 be Groundhog Day and ad-hoc toil on a bridge “just working through it.”
The bottom line: Orchestrating MIM to reduce MTTM
In a P1, detection without orchestration is awareness without action. AIOps answers “what is happening?” Cutover Respond answers “now what do we actually do about it, together, in the next 40 minutes?” Both matter, neither replaces the other, and the enterprises taking real ground on MTTM are the ones building the architecture, not shopping for a silver bullet.
Book a demo to see Cutover Respond in action.